
OCR vs OOD
An interesting out-of-distribution (OOD) image classification problem and my first freelance data science project. I was recently emailed by an ML hobbyist who’d found my previous open-set classification project on GitHub, where I came up with a simple way to classify images in certain open-set recognition problems.
They had a “real-world” image classification problem: 1000s of images of these brass “rings” split unevenly across ~20 classes (some with 1000+ samples, some with only a couple), plus the possibility of having to classify images that don’t even fall into any of these classes. They had tackled the problem using deep learning (reporting 98% accuracy with a resnet18 CNN) and wanted to add open-set classification capabilities. Framed as a deep learning problem, we are faced with two challenges:
- Classifier bias from uneven class sizes (which can artificially push up the accuracy)
- Open-set/out-of-distribution classification: recognising a cat is an outsider in a dog-breed classification problem.
The last requirements were that, since the system was to be installed inside a robot, inference time had to be < 1 second and the system had to be robust.
Then I saw the dataset (images already square and centered):

The nature of the images changed the way I perceived the problem. The images should be classified only by what text is written on the ring, and no other features. The text is also regular and predictable. Deep learning was obviously good, given the separability of the classes, but the class size bias means it would be hard to do open-set classification, and it fundamentally ignores the meaning of the text. There were two options:
- Initial 2-class classification/modify neural network (as per the literature, e.g.). This would be fast, but performance can’t be guaranteed - we still fundamentally encouter the problems with deep learning, such as lack of interpretability of rejected samples - not to mention that modifying the original network might affect the original classifier performance. This approach felt a bit naive.
- Forgetting the ML. Some heavyweight image processing, text detection and character recognition. Then, the text can be classified using hard-coded rules. Even though the computer vision is still ML-based, the classification will be completely deterministic, interpretable and modifiable. However, the trade-off is that pixel-level image processing and the ensemble of models will be slower.
I decided on pursuing option (2), and inference time turned out to be over 1 second, but still workable, which was the cost of solving the problem in a way more based on the content of the images, rather than a text-agnostic way. The solution requires no training (instead using some good open source pretrained models), and is adjustable, since classification rules are written manually.
Get started
- Clone the repo
git clone https://github.com/Andrewwango/brass-ring-ocr.git - Put test images in
data/test_images - Install CRAFT text detector with
pip install craft-text-detector - Download pretrained text recognition model
None-ResNet-None-CTC.pthmodel fromhttps://github.com/clovaai/deep-text-recognition-benchmark#run-demo-with-pretrained-modelintodeep-text-recognition-benchmark. - Install fuzzywuzzy using
pip install fuzzywuzzy - Step through the demo notebook.
Methods
The following methodology consists of 4 stages:
- Image pre-processing
- Scene text detection
- Scene text recognition
- Word matching
First warp image from polar coordinates to obtain rectangular images. Then detect area of least activity along the rectangle length and wrap rectangle to not cut off any characters. See below for example outputs. Note how some text is upside down.

Then we pass the rectangles through the CRAFT text detector to give bounding boxes of what the model considers “words”. The three thresholds given change how likely characters are to exist and how likely characters are to be grouped into words. See example crops below. Note that there is still arbitrary orientation of the crops. Out of all the stages in the method, CRAFT performs the worst (it should get better once you tune the hyperparameters, although there must be better and faster alternatives out there).
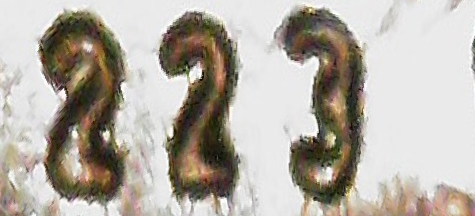
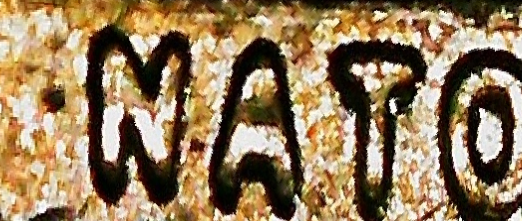
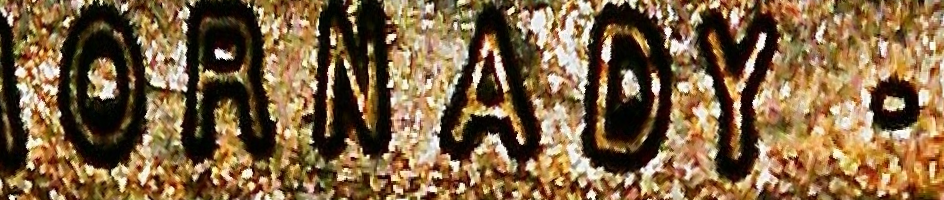
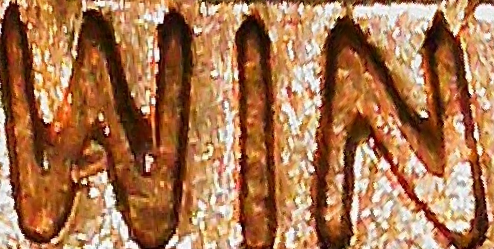
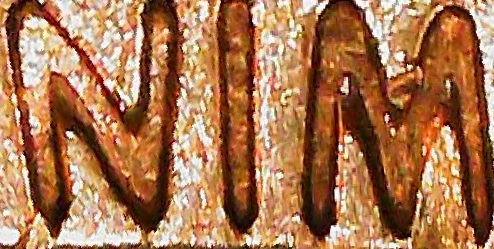
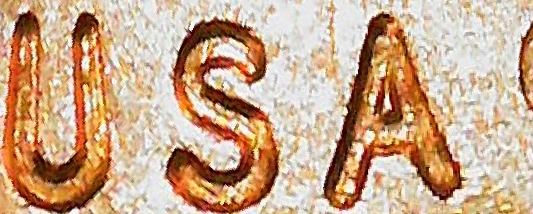
Then we pass the crops through the 4-stage scene text recognition pipeline. We don’t need their pre-processing stage nor their corpus likelihood model, since the output text isn’t standard English. Then we detect the best orientation for each segment by comparing confidences, and also pass the segments through a hardcoded rulebook - for example, NIM should always return WIN. We collect these segments into a bag of words for each image.
Finally, we run word matching. For each image, get all permutations of its bag of words, and compare each permutation with all given classes=["winusa556mm", "winnt556mm", "hornadynato556", "hornady223mm", "frontier223rem", "fc223rem"] using fuzzy word matching. Keep best match for each image, and for any score that is less than a given threshold, return REJECT signifying OOD or failure. See below for an example output dataframe.

where the first row is original filename, second row is class predictions, and third row is the matching score. We see that samples are classified to the text descriptions quite well, and the samples whose classes weren’t included in the list of classes for word matching have been rejected: they are out-of-distribution samples.
Limitations
There were two main limitations to my solution:
- The text extraction isn’t perfect on the really noisy images of rings. With more fiddling of hyperparameters of the text extraction, this should be easily remedied - requires further work. Of course, the ideal is to train the models ourselves but this will require some more preprocessing and labelling work.
- The inference time doesn’t mean the requirement. On (an old laptop’s) CPU and a batch-size of 10, inference time is roughly 7s/image for passing a sample through preprocessing, the text detection and recognition models and postprocessing. There are a few solutions to this: a. Reduce image quality b. Run on GPU/cloud - I expect this would dramatically bring the inference time down. c. Play around more with the models and remove unnecessary components, of which there are probably quite a few, since our images are quite well-behaved compared to the papers’ test images. d. Accept it - 10k images at 7s/image is still less than a day for classification!